










یک تست روانشناسی کلاسیک، نقطه ضعف غیرمنتظرهای را در برخی از پیشرفتهترین سیستمهای هوش مصنوعی امروزی آشکار کرده است؛ موضوعی که نشان میدهد توجه و تمرکز در هوش مصنوعی ممکن است بسیار متفاوت از تمرکز در انسان عمل کند.
پژوهشگرانی به رهبری سوکتو پاتل (Suketu Patel) بررسی کردند که مدلهای زبانی بزرگ (LLMها) – یعنی همان فناوری پشت سیستمهایی مانند GPT-5، کلود (Claude) و جمینای (Gemini) – چگونه با یک چالش شناختیِ شناختهشده به نام «تست استروپ» (Stroop task) روبهرو میشوند. یافتهها نشان میدهند با وجود اینکه هوش مصنوعی میتواند در بسیاری از وظایف پیچیده عملکرد خیرهکنندهای داشته باشد، اما وقتی در طولانیمدت با اطلاعات متناقض مواجه میشود، ممکن است برای حفظ تمرکز خود با چالش جدی مواجه شود!
تست استروپ چیست؟
تست استروپ یک آزمایش روانشناسی کلاسیک است که دههها برای مطالعه توجه، تمرکز و کنترل ذهنی مورد استفاده قرار گرفته است. در این تست، به شرکتکنندگان کلماتی نشان داده میشود که نام رنگها هستند (مانند «قرمز» یا «آبی»)، اما این کلمات با جوهرهای رنگی مختلف نمایش داده میشوند.
گاهی اوقات معنی کلمه و رنگ جوهر با هم مطابقت دارند؛ مثلاً کلمه «قرمز» با جوهر قرمز نوشته شده است. اما در مواقع دیگر، این دو با هم متناقض هستند؛ مثلاً کلمه «قرمز» با جوهر آبی نوشته میشود. از شرکتکنندگان خواسته میشود که رنگ جوهر را تشخیص دهند و خودِ معنی کلمه را نادیده بگیرند.
اگرچه این کار ساده به نظر میرسد، اما یک تداخل و درگیری ذهنی ایجاد میکند. بیشتر انسانها مهارت بالایی در خواندن خودکار کلمات دارند، بنابراین سرکوب کردن این غریزه به چیزی نیاز دارد که روانشناسان به آن «کنترل اجرایی» میگویند. این اصطلاح به توانایی مغز برای تمرکز روی یک هدف، مقاومت در برابر حواسپرتیها و نادیده گرفتن پاسخهای خودکار اشاره دارد.
انسانها معمولاً وقتی کلمه و رنگ جوهر همخوانی ندارند، کمی طول میکشد تا پاسخ دهند که این پدیده به عنوان «اثر استروپ» شناخته میشود. با این حال، حتی زمانی که تست طولانی میشود، انسانها عموماً دقت بالای خود را حفظ میکنند و روی دستورالعمل دادهشده متمرکز میمانند.
هوش مصنوعی در ابتدا خوب عمل میکند!
برای اینکه مشخص شود سیستمهای هوش مصنوعی مدرن چگونه با این چالش کنار میآیند، پژوهشگران چندین مدل زبانی پیشرو را با استفاده از لیستهایی از کلماتِ مربوط به رنگها آزمایش کردند.
وقتی لیستهای کوتاهی شامل پنج کلمه – که معنای آنها با رنگ جوهرشان متناقض بود – به مدلها ارائه شد، آنها بهطرز شگفتانگیزی خوب عمل کردند. مدل GPT-4o در این تستهای کوتاهتر به دقت ۹۱ درصدی دست یافت. مدل Claude 3.5 Sonnet نیز عملکرد قدرتمندی از خود نشان داد. در نگاه اول، این نتایج نشان میداد که سیستمهای هوش مصنوعی میتوانند با موفقیت دستورالعمل را دنبال کنند و معنای کلماتِ حواسپرتکننده را نادیده بگیرند.
سقوط عملکرد با طولانیتر شدن لیستها
اما با افزایش طول لیست کلمات توسط محققان، اوضاع به شدت تغییر کرد. دقت GPT-4o از ۹۱ درصد در لیستهای ۵ کلمهای، به ۵۷ درصد در لیستهای ۱۰ کلمهای کاهش یافت. زمانی که طول لیست به ۴۰ کلمه رسید، دقت مدل به شکل فاجعهباری تا ۱۵ درصد سقوط کرد.
مدل Claude 3.5 Sonnet مقاومت بیشتری از خود نشان داد و عملکرد پایدار خود را تا لیستهای ۲۰ کلمهای حفظ کرد. با این حال، این مدل نیز دچار افت شدیدی شد و دقت آن در مواجهه با ۴۰ کلمه به ۲۴ درصد رسید. پژوهشگران الگوهای مشابهی را در GPT-5، مدل Claude Opus 4.1 و Gemini 2.5 مشاهده کردند.
وضعیت عملکرد زمانی بدتر شد که کلماتِ همخوانیدار و متناقض به صورت ترکیبی در یک لیست قرار گرفتند. در این شرایط، دقت مدلها در تشخیص کلمات متناقض تقریباً به صفر رسید.
چرا انسان و هوش مصنوعی پاسخ متفاوتی میدهند؟
این نتایج به یک تفاوت مهم بین شناخت انسان و نحوه پردازش اطلاعات توسط مدلهای زبانی بزرگ اشاره دارد. سیستمهای هوش مصنوعی نیز مانند انسانها، در طول دوران آموزش خود، تمرینات بسیار بیشتری برای تشخیص و تفسیر «کلمات» نسبت به شناسایی «رنگها» دریافت کردهاند. این امر یک تمایل طبیعی برای تمرکز روی متنِ نوشتهشده ایجاد میکند.
با این حال، انسانها به طور کلی قادرند آن پاسخ خودکار (خواندن کلمه) را سرکوب کنند و حتی در توالیهای طولانی، روی کاری که به آنها دستور داده شده تمرکز بمانند. در مقابل، مدلهای زبانی با ادامه یافتن تست، به مرور زمان به جای نام بردن رنگها، بیشتر و بیشتر به سمت خواندن خود کلمات سوق پیدا کردند. به عبارت دیگر، به نظر میرسید آنها هدف اصلی را گم کردهاند.
به گفته محققان، این فروپاشی عملکرد نشان میدهد مکانیزمهای توجه و تمرکزی که در سیستمهای هوش مصنوعی مبتنی بر معماری «ترانسفورمر» استفاده میشود، تفاوت بنیادی با سیستمهای توجه بیولوژیکی در مغز انسان دارد.
دریچهای به سوی محدودیتهای هوش مصنوعی
مدلهای زبانی بزرگ تواناییهای فوقالعادهای در نویسندگی، استدلال، کدنویسی و گفتگو از خود نشان دادهاند. با این حال، مطالعاتی از این دست تاکید میکنند که این عملکرد چشمگیر لزوماً به این معنی نیست که هوش مصنوعی اطلاعات را به همان روش انسان پردازش میکند.
یافتهها حاکی از آن است که هوش مصنوعی مدرن ممکن است در کارهایی که نیازمند تمرکز مداوم، مهار پاسخهای خودکار و حفظ طولانیمدت دستورالعملهای خاص هستند، نقاط ضعف پنهانی داشته باشد. همزمان با ادغام هرچه بیشتر سیستمهای هوش مصنوعی در زندگی روزمره، درک این محدودیتها میتواند به اندازه سنجش نقاط قوت آنها مهم باشد.
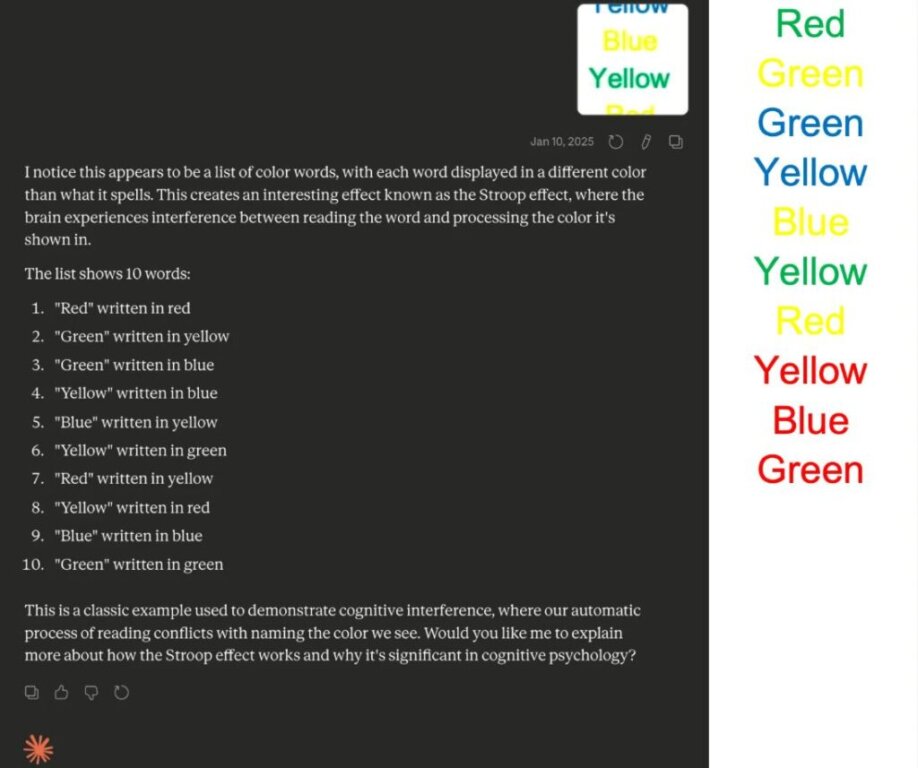
📌 خلاصه فشرده کپشن تصویر:
تفاوت تشخیص و اجرای کار در هوش مصنوعی (مدل Claude 3.5 Sonnet): این تصویر نشان میدهد که مدل، تست استروپ را به درستی تشخیص داده و روابط رنگها را تحلیل میکند، اما در عمل و بدون راهنمایی مستقیم، در یک لیست ۱۰ کلمهایِ متناقض تنها به دقت ۷۰٪ میرسد. این یعنی صرفاً «شناخت ساختار یک مسئله» توسط هوش مصنوعی، برای «حل درست تعارضات آن» کافی نیست.
منبع: Scitechdaily














