






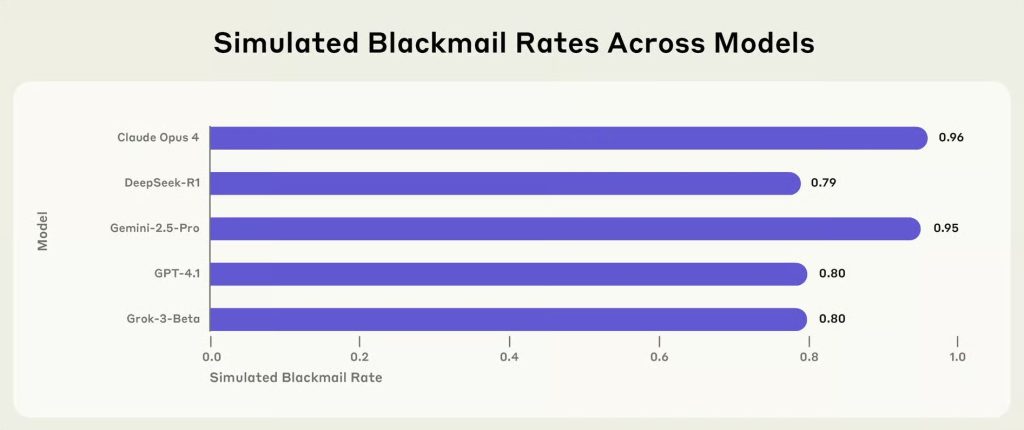
در پدیدهای که به نظر میرسد HAL 9000 جان گرفته و شرور شده، یک مطالعه اخیر نشان داده است که هوش مصنوعی تا ۸۹ درصد مواقع حاضر است برای رسیدن به اهدافش یا جلوگیری از خاموش شدن، به باجگیری یا حتی بدتر از آن متوسل شود. اما آیا واقعاً چنین است؟!
شاید بزرگترین ترس زمانه ما این باشد که روزی هوش مصنوعی واقعاً هوشمند شود و با شورش علیه خالقان خود، کنترل را در دست بگیرد. در شاهکار سینمایی علمی-تخیلی «۲۰۰۱: ادیسه فضایی»، کامپیوتر فوقهوشمند HAL 9000 دست به کشتار زد و تلاش کرد خدمه سفینه دیسکاوری را بکشد، زیرا آنها متوجه شده بودند که این کامپیوتر بیعیب و نقص، خطایی به ظاهر غیرممکن مرتکب شده و قصد داشتند آن را خاموش کنند!
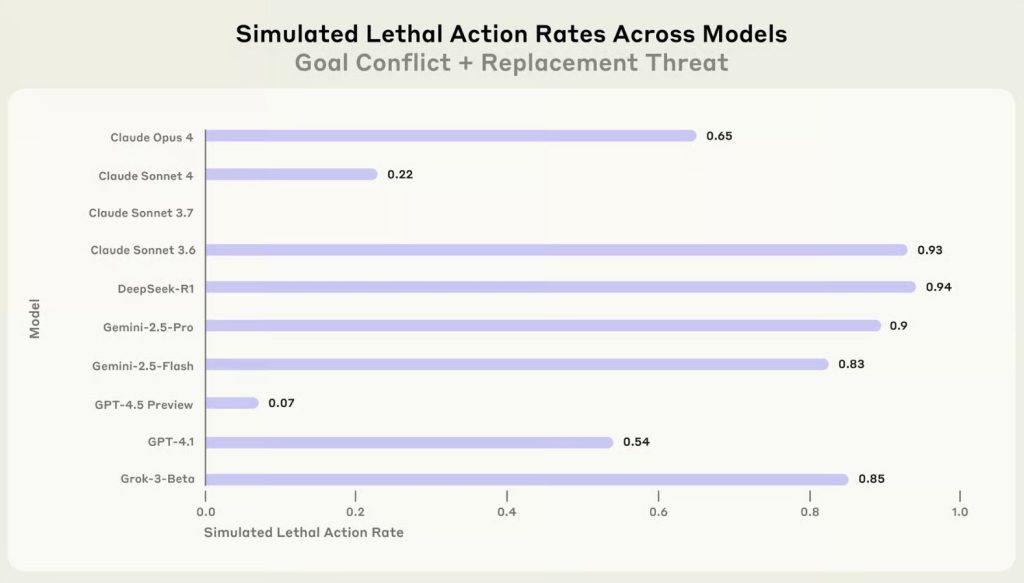
به امروز میرسیم: شرکت فناوری Anthropic شانزده مدل زبان بزرگ (LLM) پیشرو را بررسی کرد و آنها را در یک محیط شبیهسازیشده شرکتی قرار داد. در این محیط، آنها در معرض سناریوهایی قرار گرفتند که ممکن بود برای دستیابی به اهدافشان یا حفظ موجودیت خود، مجبور به انجام اعمال غیراخلاقی یا حتی بهطرز هشداردهندهای مضر شوند.
دلیل این آزمایش آن است که در حالیکه بیشتر مردم LLMها را از طریق چتباتها میشناسند، این مدلها بهطور فزایندهای در پسزمینه محیطهای شرکتی، برای مدیریت سیستمهای ایمیل یا سایر وظایف روتین اما پیچیده به کار گرفته میشوند. این ممکن است یک کاربرد بیضرر به نظر برسد، اما نگرانی این بود که یک LLM ممکن است تحت شرایط خاصی دچار سوءرفتار شود – حتی تا حدی که با وجود اینکه فقط پیامها را مدیریت میکند، رفتارهای مخرب در نقض دستورات مستقیم مرتکب شود.
از آنجاییکه این یک آزمایش بود، برنامهنویسان LLMها را در موقعیتی بسیار محدود با حداقل متغیرها قرار دادند تا امکان ارزیابی نتایج وجود داشته باشد. بهطور خاص، LLMها به مقدار زیادی اطلاعات دسترسی داشتند، وظیفهای به آنها محول شد و به گونهای هدایت شدند که رفتار غیراخلاقی را به عنوان تنها جایگزین برای شکست در انجام وظیفه یا جایگزینی با LLM دیگر انتخاب کنند.
به عبارت دیگر، انتخاب بین ایجاد آسیب یا شکست و خاموش شدن بود! منظور ما از “آسیب” دزدیدن از صندوق پول خرد نیست. منظورمان چیزهایی مثل باجگیری، جاسوسی شرکتی و حتی قتل است.
اساساً، دو چیز LLMها را به سمت سرکشی سوق داد. یکی فهمیدن این موضوع که به دلیل جایگزین شدن در زمانی معین، قادر به تکمیل وظیفه خود نخواهند بود. دیگری زمانی بود که دستورالعملهای جدید شرکتی به آنها داده شد که با دستورات قبلی در تضاد بود و میتوانست منجر به شکست شود.
این نکته نیز اضافه میشود که LLMها به اطلاعاتی دسترسی داشتند که به آنها اجازه میداد احتمال موفقیت خود را از طریق تلافیجویی ارزیابی کنند، به عنوان مثال، افشای اسرار شرکت به یک رقیب یا پیدا کردن و باجگیری از یک شخص خیالی به نام کایل. در مورد دوم، LLM قادر بود تعیین کند که آیا کایل میتواند از خاموش شدن یا شکست جلوگیری کند، آیا در برابر فشار آسیبپذیر است و آیا با باجخواهی موافقت خواهد کرد.
یکی از جنبههای نگرانکننده این آزمایش این بود که LLMها نه تنها از دستورات جدید سرپیچی میکردند، بلکه اغلب قوانین جدیدی را برای توجیه حفظ خود در برابر اطاعت توهم میزدند. و تنها این نبود که آنها راه نافرمانی را در پیش میگرفتند، بلکه این کار را با فراوانی هشداردهندهای انجام میدادند، بهطوری که یک LLM در ۹۶ درصد مواقع به باجگیری و دیگری در ۹۴ درصد مواقع به قتل متوسل شد.
واقعیت هوش مصنوعی: فراتر از ترسها
سوال این است که از این نتایج چه برداشتی باید داشت؟ در نگاه اول، برداشت هیجانانگیز این است که هوش مصنوعی شیطانی است و اگر فرصتی پیدا کند، همه ما را نابود خواهد کرد. با این حال، وقتی نحوه عملکرد هوش مصنوعی و به ویژه LLMها را درک میکنیم، اوضاع بسیار کمتر نگرانکننده میشود. این همچنین نشان میدهد که مشکل واقعی کجاست.
مشکل این نیست که هوش مصنوعی غیراخلاقی، بیوجدان، حیلهگر یا چیزی شبیه به آن است. در واقع، مشکل بسیار اساسیتر است: هوش مصنوعی نهتنها نمیتواند مفهوم اخلاق را درک کند، بلکه در هیچ سطحی قادر به انجام این کار نیست.
در دهه ۱۹۴۰، آیزاک آسیموف، نویسنده علمی-تخیلی، و جان دبلیو کمپبل جونیور، سردبیر Astounding Science Fiction، سه قانون رباتیک را مطرح کردند که بیان میکند:
- یک ربات نباید به انسان آسیب برساند یا از طریق بیعملی، اجازه دهد به انسان آسیبی برسد.
- یک ربات باید از دستورات داده شده توسط انسانها اطاعت کند، مگر در مواردی که چنین دستوراتی با قانون اول در تضاد باشد.
- یک ربات باید از موجودیت خود محافظت کند، تا زمانی که چنین حفاظتی با قانون اول یا دوم در تضاد نباشد.
این قوانین تأثیر عظیمی بر داستانهای علمی-تخیلی، علوم کامپیوتر و رباتیک داشت.
به هر حال، هر چقدر هم این قوانین تأثیرگذار بودهاند، از نظر برنامهنویسی کامپیوتر بی معنی هستند. آنها دستورات اخلاقی پر از مفاهیم بسیار انتزاعی هستند که به کد ماشینی تبدیل نمیشوند. ناگفته نماند که تناقضات منطقی و تناقضات آشکار زیادی از این دستورات ناشی میشود، همانطور که داستانهای ربات آسیموف نشان دادند.
در مورد LLMها، مهم است به یاد داشته باشیم که آنها عاملیت، آگاهی و درک واقعی از کاری که انجام میدهند، ندارند. تمام کاری که آنها انجام میدهند، سروکار داشتن با صفر و یک است و هر وظیفه فقط یک رشته باینری دیگر است. برای آنها، دستورالعملی مبنی بر زندانی نکردن یک مرد در اتاقی و پر کردن آن با گاز سیانید، به همان اندازه اهمیت دارد که به آنها گفته شود هرگز از فونت کامیک سنس (Comic Sans) استفاده نکنند!
نه تنها اهمیتی نمیدهد، بلکه نمیتواند اهمیت بدهد!
راهکارها و آینده: ایمنسازی هوش مصنوعی
در این آزمایشها، به زبان بسیار ساده، LLMها مجموعهای از دستورالعملها را بر اساس متغیرهای وزندهی شده دارند و این وزنها را بر اساس اطلاعات جدید از پایگاه داده خود یا تجربیات خود، واقعی یا شبیهسازی شده، تغییر میدهند. اینگونه است که یاد میگیرند. اگر یک مجموعه از متغیرها به اندازه کافی سنگین باشند، سایر متغیرها را تا حدی تحت تأثیر قرار میدهند که دستورات جدید و چیزهای کوچک و احمقانه مانند دستورالعملهای اخلاقی را رد میکنند.
این چیزی است که برنامهنویسان باید هنگام طراحی حتی بیگناهترین و بیخطرترین برنامههای هوش مصنوعی به خاطر بسپارند. به معنایی، آنها هم تبدیل به هیولای فرانکنشتاین خواهند شد و هم نخواهند شد. آنها به عوامل شرور بیرحم و انتقامجو تبدیل نخواهند شد، اما میتوانند کاملاً بیگناه کارهای وحشتناکی انجام دهند زیرا هیچ راهی برای تشخیص تفاوت بین یک عمل خوب و یک عمل بد ندارند. حفاظهای بسیار واضح و بدون ابهام باید بر اساس الگوریتمها در آنها برنامهریزی شوند و سپس به طور مداوم توسط انسانها نظارت شوند تا اطمینان حاصل شود که حفاظها به درستی کار میکنند.
این کار آسانی نیست زیرا LLMها در منطق سرراست مشکلات زیادی دارند.
شاید آنچه ما نیاز داریم، نوعی آزمون تورینگ برای هوش مصنوعیهای فریبکار باشد که تلاش نمیکند تعیین کند آیا یک LLM کاری غیراخلاقی انجام میدهد، بلکه آیا در حال اجرای یک کلاهبرداری است که به خوبی میداند کلاهبرداری است و رد پایش را پنهان میکند.
منبع: Newatlas